Get Timeseries data at Points in Space
What is a Timeseries
A timeseries is a collection of observations in chronological order. These could be daily stock closing prices, the daily temperature of a given location, or any other data point that changes over time. Timeseries data is a fundamental building block of a data specialist's analysis and solutions. As it is a simple and explainable method of understanding changes to a variable over time. This function enables users to extract the timeseries data of a given list of geospatial point/s from a gridded dataset.
Gridded Data Structure and Extraction
Most Gridded data is three-dimensional, the Eratos standard is to define these dimensions in Time, Latitude, and Longitude.
The below figure is a visualization of those 3 dimensions, longitude on the x-axis, latitude on the y-axis, representing location, and time on the z-axis.

As seen below, every cube is defined by discrete intervals in all 3 dimensions, in this example x and y increment in 1 degree intervals, whereas the time increment is dependent on the temporal frequency of the underlying dataset, the specific intervals for a given dataset can be found through the: Print Gridded Dataset Metadata function.
Here we have extracted two individual timeseries starting on the 1st of January 2021 (2021-01-01) and ending a year later (2022-01-01) at Point (147, -42) and Point (150, -44).

Get Timeseries at Points Function
You can extract desired timeseries data at a given point of an Eratos gridded dataset using the get_timeseries_at_points function which has the following definition:
res = edata_gridded.get_timeseries_at_points(
var,
point_list,
startDate,
endDate,
time_stride = 1,
)res = edata_gridded$get_timeseries_at_points(
var,
point_list,
startDate,
endDate,
time_stride = 1,
)where
edata_gridded: A gridded Eratos dataset that contains the key variablevar: The variable key of the variable to fetchpoint_list: An array of points with a minimum of 1startDate: The start date for the fetched timeseries: "2021-01-01" or
datetime "2021-01-01T00:00:00Z" following the Eratos Date-Time Data StandardsendDate: The end date for the fetched timeseries: "2022-01-01" or
datetime "2022-01-01T00:00:00Z"time_stride: The stride in the time dimension, for a dataset with a daily temporal frequency time_stride = 2, would extract every second day, default = 1
Function Standard Use Case
#Eratos adapter and credentials system
from eratos.creds import AccessTokenCreds
from eratos.adapter import Adapter
import pandas as pd
from tabulate import tabulate
from getpass import getpass
eratos_id = getpass('Enter the eratos key id:')
eratos_secret = getpass('Enter the eratos secret:')
ecreds = AccessTokenCreds(
eratos_id,
eratos_secret
)
eadapter = Adapter(ecreds)
# Pull a dataset resource in Eratos via it's unique ern
max_temperature_data = eadapter.Resource(ern='ern:e-pn.io:resource:eratos.blocks.silo.maxtemperature')
# Access the gridded dataset via the Gridded API:
gridded_max_temperature_data = max_temperature_data.data().gapi()
# Query the Gridded API to see what variables are inside the dataset
print(dict.keys(gridded_max_temperature_data.variables()))
# Define the functions input variables following Eratos' data standards
startDate = "2021-01-01"
endDate = "2022-01-01"
#9 times out of 10 this will be the variable you are after, in this case ('max_temp')
var = gridded_max_temperature_data.get_key_variables()[0]
# Points in Australia, Federation Square, Melbourne and Sydney Opera House.
point_name = ['Federation Square, Melbourne','Sydney Opera House']
point_list = ['POINT(144.968654 -37.817960)','POINT(151.215177 -33.857169)']
# Key Function
extracted_data = gridded_max_temperature_data.get_timeseries_at_points(var, point_list, startDate, endDate)
print(extracted_data.shape)
# Generate all days between startDate and endDate
date_generated_list = pd.date_range(startDate, endDate, freq="D")
date_range = date_generated_list.strftime("%Y-%m-%d").to_list()
# Create dataframe
data_dict = {"date":date_range,point_name[0]:extracted_data[0],point_name[1]:extracted_data[1]}
data_frame = pd.DataFrame(data_dict)
print(tabulate(data_frame.head(), headers='keys', tablefmt='fancy_grid'))reticulate::use_condaenv("eratoslabs", required=TRUE)
library(reticulate)
library(rjson)
eratosAdapter <- reticulate::import("eratos.adapter")
eratosCreds <- reticulate::import("eratos.creds")
path_to_eratos_creds = "PATH_TO_CREDS_AS_JSON_FILE"
creds = fromJSON(file = path_to_eratos_creds)
at <- eratosCreds$AccessTokenCreds(creds$key[1], creds$secret[1])
ad <- eratosAdapter$Adapter(at)
# Pull a dataset resource in Eratos via it's unique ern
max_temperature_data = ad$Resource(ern='ern:e-pn.io:resource:eratos.blocks.silo.maxtemperature')
# Access the gridded dataset via the Gridded API:
gridded_max_temperature_data = max_temperature_data$data()$gapi()
# Query the Gridded API to see what variables are inside the dataset
gridded_max_temperature_data$variables()
# Define the functions input variables following Eratos' data standards
startDate <- "2021-01-01"
endDate <- "2022-01-01"
# max_temp, as found in the dataset variables
var <- gridded_max_temperature_data$get_key_variables()[1]
# Points in Australia, Federation Square, Melbourne and Sydney Opera House.
point_list <- c('POINT(144.968654 -37.817960)','POINT(151.215177 -33.857169)')
# Key Function
extracted_data = gridded_max_temperature_data$get_timeseries_at_points(var, point_list, startDate, endDate)
print(extracted_data)Output
The first 5 rows of the table below show the maximum temperature for a given day at Federation Square, Melbourne (POINT(144.96 -37.81) and Sydney Opera House POINT(151.21 -33.85).

The output for get_timeseries_at_points is a 2D Numpy Array Object with the shape:(2, 366)
Here the 2 represents the 2 location points we requested in chronological order. extracted_data[0] will return the Maximum Temperature in Celsius for the 366 days of 2021 at Point(147, -42), with the first value representing the Maximum Temperature on 01-01-2021, and the last on 01-01-2022.
Transforming this data into a _pandas _ data frame gives the following results with data_frame.head()
Learn how this function is used to gain insights about our physical world
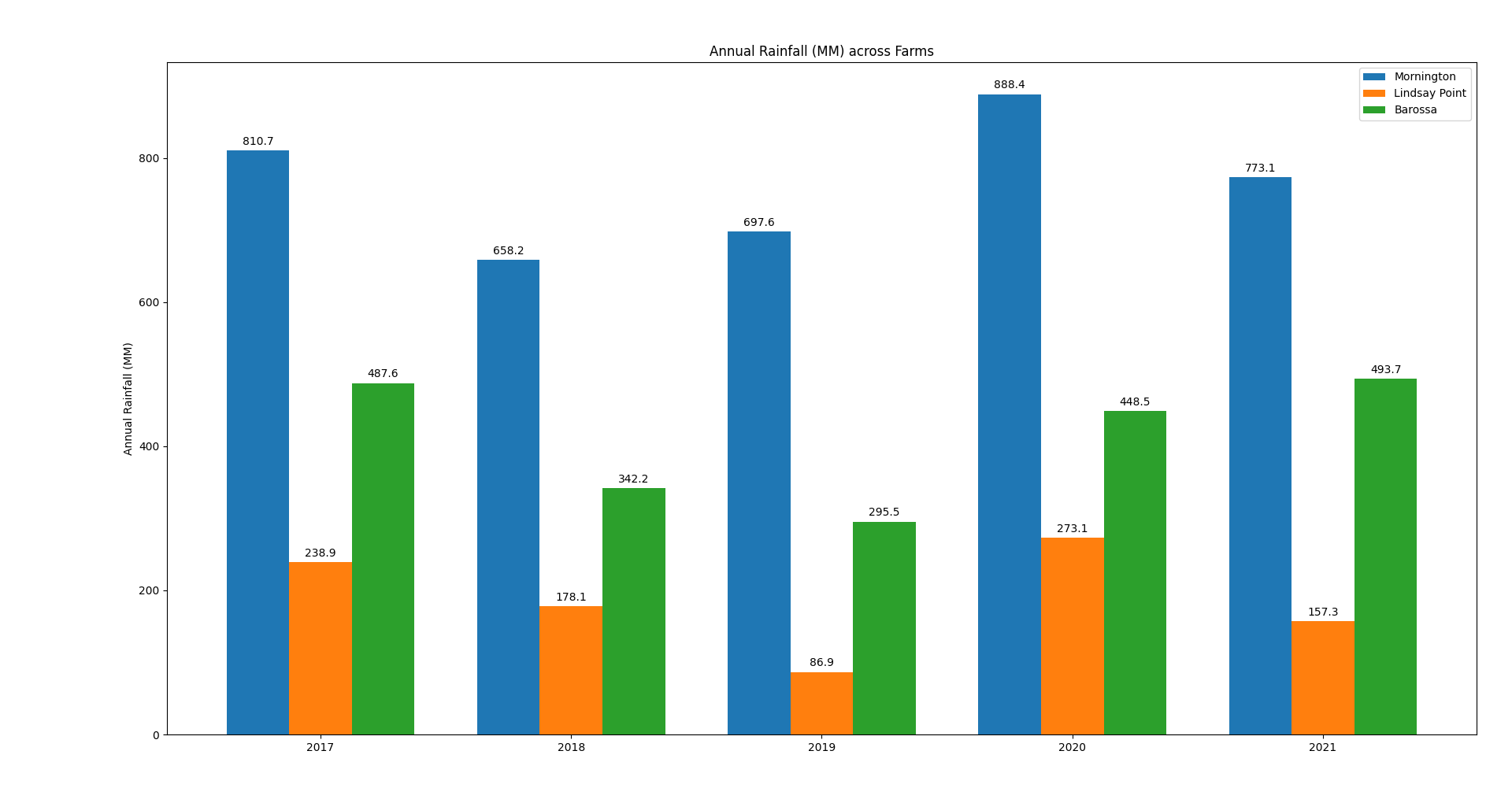
Annual Rainfall: Produced from the above Guide (Click to enlarge)
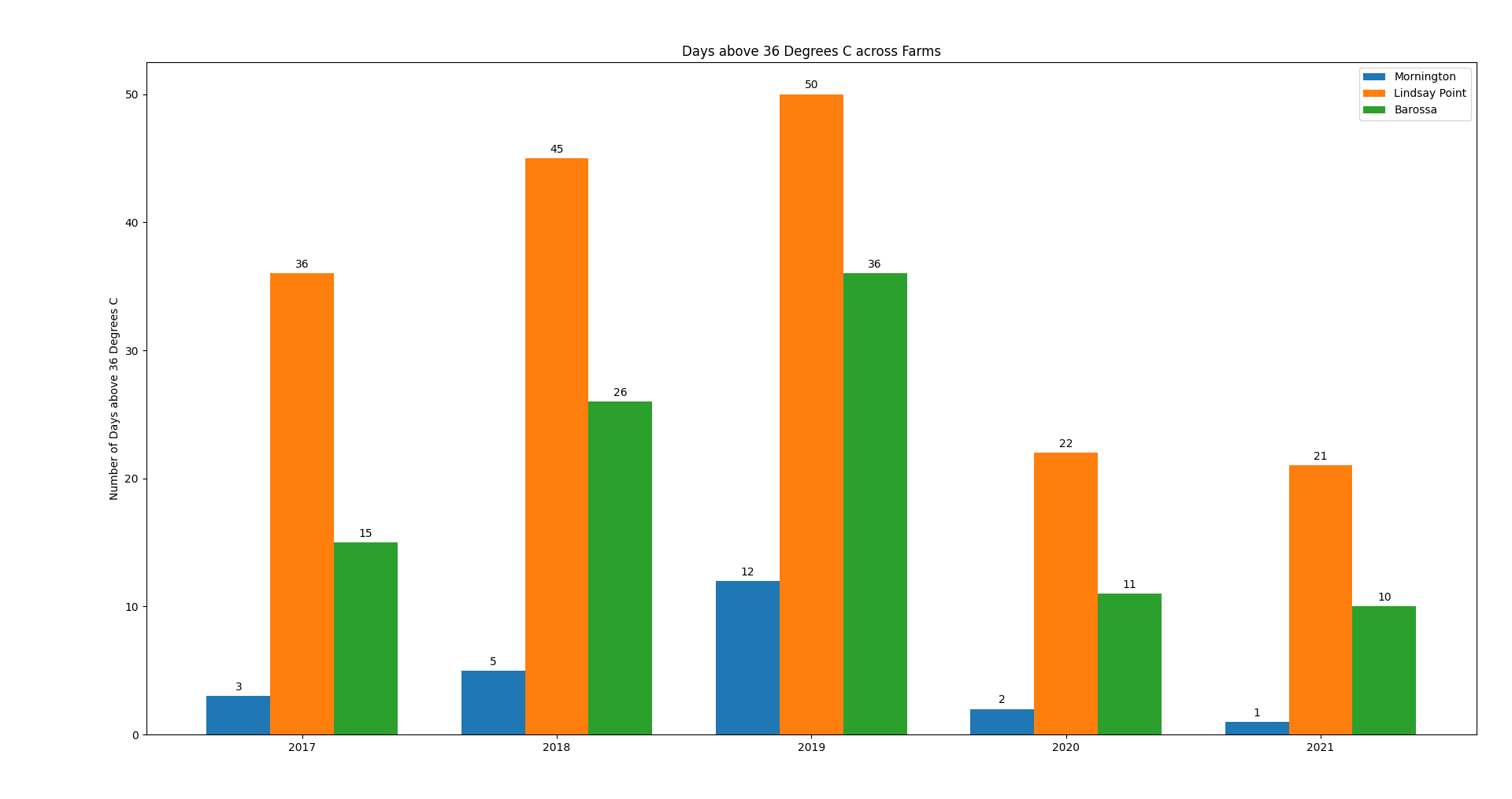
Days above 36 Degrees C: Produced from the above Guide (Click to enlarge)
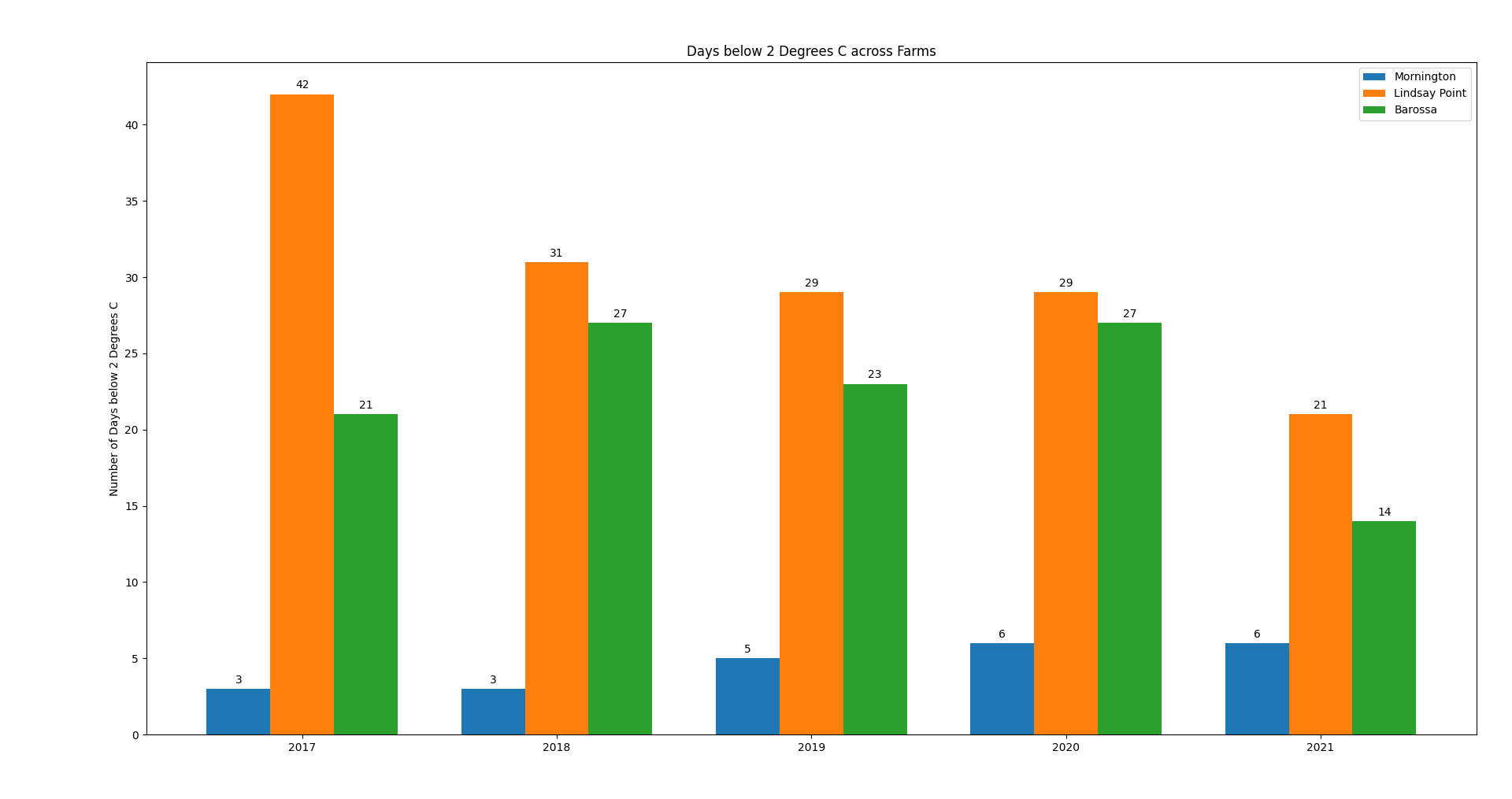
Days below 2 Degrees C: Produced from the above Guide (Click to enlarge)